How I Built The Dynamic Workflow 4 Months Before Anthropic
Last week, Opus 4.8 shipped with Claude Code dynamic workflows. Four months earlier, I had built an equivalent plugin, charge, on Opus 4.5: you give it a prompt, and it creates and orchestrates reusable subagent-driven workflows.
“Charge” here means sending a lot of subagents charging into the task you assigned.
I abandoned the project soon after since dynamically spawning and reusing subagent workflows turned out to be a false need. However, subagent-based orchestration remains central to my daily work in Claude Code—now through amplify (amplify@wezzard-skills), which applies lessons I learned in building charge.
If you build agents, I hope this story helps you spot the next meaningful capability jump in a new model—and design systems like Claude Code's dynamic workflow without repeating my detours. Anthropic does not publish implementation details or design notes; this post and open repos do.
Why I Built Charge?
Since August 2025, I had been running a long-running agentic loop with detailed plan files to drive development of my personal projects in Claude Code with Opus 4.1.
In practice, it was a subagent-driven loop. Subagents segregate context well because LLMs work by next-token prediction; one of the most efficient ways to improve a system's bottom line is to keep unnecessary content out of context.
The loop includes an evaluator and several executor subagents that carry out development, testing, troubleshooting, and integration gatekeeping against the plan. Each step benefits from the context segregation subagent-driven design provides.
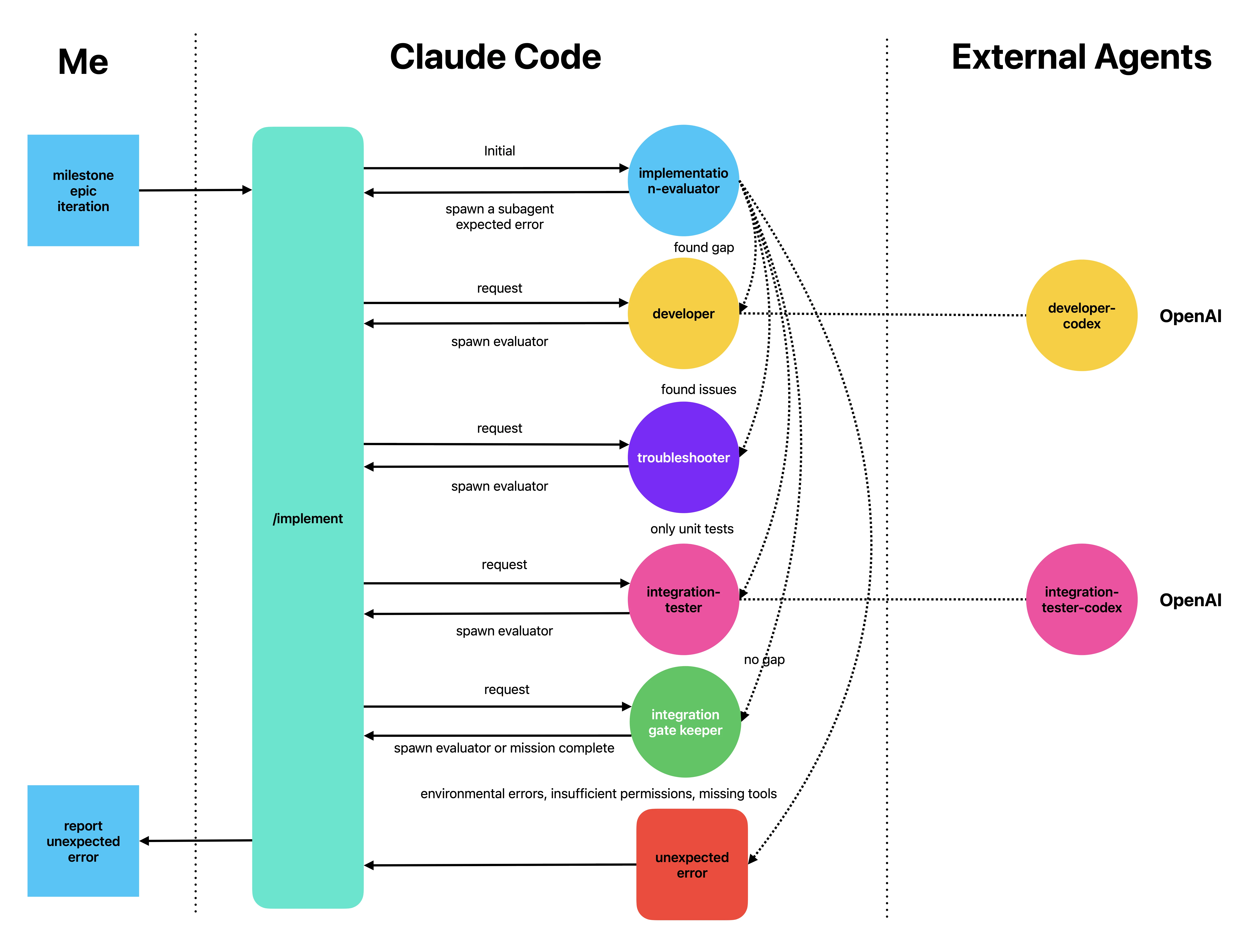
In September 2025, I published a post explaining how the system works. Two months later, Anthropic published a post that introduced the "harness" concept with a similar design.
When Opus 4.5 shipped, the main agent would sometimes skip the evaluator-executor pattern of this loop and push work to completion on its own since subagent responses carried details about the in-loop task. Almost the same time, Claude Code had just introduced background tasks and parallel subagents. With these new features, the leak-to-main-agent phenomenon often ran faster anyway, because leaked tasks were sometimes decomposed and processed in parallel. By January 2026, I had spawned more than 70 parallel subagents in a file-processing task on Claude Code.
Adding it all up, from Opus 4.5 onward, running and coordinating subagents became much easier. That raised a question: what if I could create and manage reusable workflows driven by subagents, and build dependencies between them by borrowing concepts from structured concurrent programming—task trees and directed acyclic graphs?
Implementation Details and Design Philosophy
The implementation details of charge are simple: prompts drive it, and dynamically generated schemas enforce it. charge is open source; below I highlight implementation points that readers often mistake for "magic."
Task Decomposition and Dependencies
Task decomposition and dependency building are achieved by the chain-of-thought technique in the following steps:
- Understand the user's intent
- Identify repetitive patterns in the user's intent
- Identify task boundaries so each task has a single, clear purpose and identifiable inputs and outputs.
- Define task properties used in the task's schema.
- Map dependencies to a task dependency graph.
Following this chain of thought, the model converts a simple user prompt into a JSON object that represents the dependency graph of decomposed tasks:
json
Tasks live in the tasks array; each has a depends_on field for its dependencies. The workflow executor consumes this JSON object.
The Execution Engine
Read the task dependency graph from that JSON object, and Claude Code can "magically" run tasks in dependency order.
Anthropic implemented this part with a deterministic execution engine written in JS, which I think is the right move for a system meant to orchestrate subagents at scale. LLMs work by next-token prediction; a prompt-based execution engine must rely on the model to infer execution order and emit the correct tool call to launch the next agent when a predecessor finishes—neither is guaranteed.
However, despite wiring all the subagents with JS, you can implement the engine with the generator pattern and run it in the main agent:
shell
With this design, the main agent of Claude Code still orchestrates the workflow. It counts on the model to call complete-task.sh when an agent finishes a task and to spawn new subagents from the tool output.
Cost and Correctness
When a workflow is built and about to execute, charge uses Claude Code's plan mode to let the user review the decomposed workflow.
This review step matters because dynamically generating subagents from tasks is billed as output tokens—the main agent outputs the spawning prompts for those subagents—which is far more expensive than input tokens. You can read the design as "progressive disclosure" in token consumption.
Control and Steering
Here charge has another edge over Claude Code's dynamic workflows. Because workflow orchestration in charge stays in the main agent, you can interrupt and steer at any point during execution.
Why I Call It a False Need
After using charge for a while, I found that the most reused workflows in the real world are better represented with deterministic algorithms. That work belongs in code, not prompts.
Introduce an LLM only when creativity is required. In reusable workflows, LLMs commonly appear in analysis tasks, diagnostic tasks, or "code laundering" tasks like laundering Bun from Zig to Rust, which Anthropic listed as a showcase of dynamic workflows. If you are creating something totally new, keeping the human in the loop and steering as you go is the right choice.
Even for analysis and diagnostic tasks, you can still write code to produce better-structured, more digestible tool outputs and to coalesce tool calls by inlining multiple tool calls in a script. That improves execution speed and reduces noise in context. These optimizations matter because they can improve workflow performance and the quality of results—and we care whether an analysis or diagnosis yields a feasible suggestion.
On top of that, for tasks where feasibility matters, you can build upon an agent SDK like OpenCode SDK to introduce type safety in data transfer and in-process communication instead of inter-process tool calls. OpenCode SDK and OpenCode share the same session format. This means an OpenCode SDK session can be resumed in the OpenCode client. This interoperability introduces debuggability to an LLM-driven workflow—an overlooked gem in the agent ecosystem.
Research tasks are an exception. Research sits too far from actionable output; many judgments remain before you turn research into action. I think that is why Claude Code bundles a /deep-research workflow.
Here is a decision tree to help you pick the right tool:
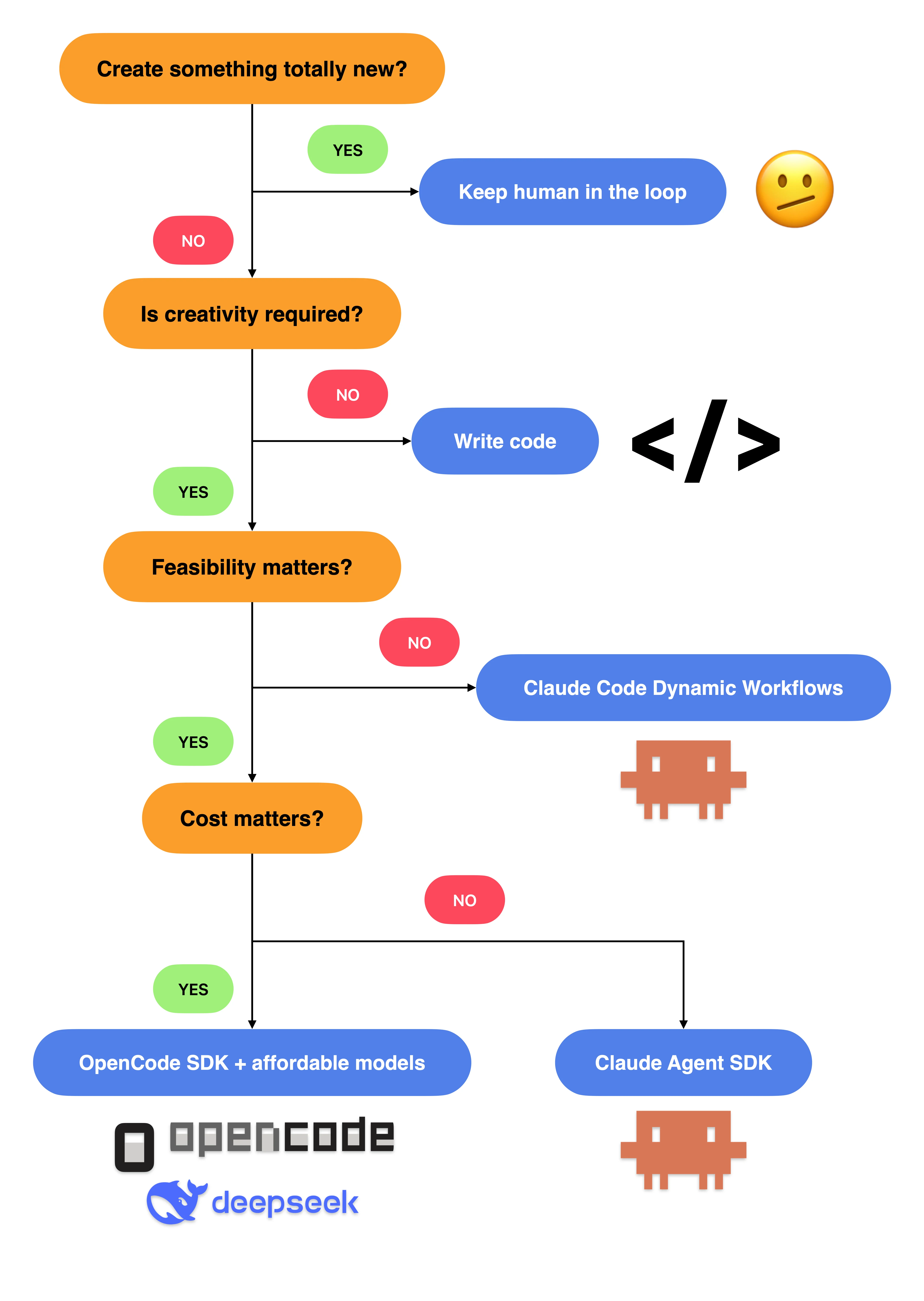
Where I Landed
With that decision tree in hand, it comes down to:
- To create something totally new, we still need to keep the human in the loop to steer the agent as we go.
- To perform reusable workflows, we can choose more economical options: build with OpenCode and an affordable model, or write code that only costs CPU time, not tokens.
The first item is the bottleneck in my daily use of Claude Code.
I then created amplify in Feb, 2026 by borrowing the following design elements from charge:
- Task dependency graph and per-task subagent.
- The plan-based task graph review.
- Execute in the main agent to allow steering as you go.
To prevent Claude Code from ending prematurely, amplify also introduces audit subagents that check whether the planned work was actually completed.